INFORMATION
テクノロジ
Spark + AI Summit Europe に参加しました!
著者:ゴンザレス エルピディオ
2019年10月14〜16日にオランダで開催されたSpark + AI Summit Europeにロンウイットの代表として参加してきました。イベントは、アムステルダムのZuidasビジネス地区にあるRAIコンベンションセンターで開催されました。Spark + AI Summit Europeはヨーロッパ最大のデータおよび機械学習カンファレンスであり、毎年63か国から2,000人以上が参加しています。本カンファレンスは主にキーノート、事例発表のセッション、ワークショップ、トレーニングで構成されています。どのトピックにおいても Apache Spark™ や TensorFlow などのオープンソーステクノロジーの最新の動向と、AIを現実世界に展開するためのベストプラクティスが得られることが特徴です。 以下に、有償トレーニングの内容と特に興味深いと思ったキーノートとセッションを簡単にまとめます。


トレーニング(初日)
簡単なセルフチェックインの後、バッジを受け取り、トレーニングセッションが行われる会議室に向かいました。今年は7つのトレーニングコースがあり、私は Data Science with Apache Sparkというワークショップに参加しました。トレーニングは予定通りに午前9時に始まりました。必要な事前準備の手順やトレーニングの公式Slackチャンネルへのリンクは、イベントの約1週間前にメールで通知されていたおかげでトレーニングはスムーズに進んだと思います。 このトレーニングの目的は、Apache Spark を使用して探索的データ分析(Exploratory Data Analysis)を実行し、機械学習パイプラインを開発、Spark MLlib DataFrames API で利用可能な API とアルゴリズムを学習することでした。各参加者には、クラスで使用するために個別の Azure Databricks アカウントが割り当てられました。 トレーニングはまず、 Apache Spark の概要を講義され、その後8つの Azure Databricks ノートブックを使って演習を行う流れでした。各ノートブックは、予測機械学習モデルの開発ステップごとに分かれていました。ノートブックの前半では、データクレンジングと線形回帰モデルの基礎的なことについて学べ、後半では XGBoost や MLeap など、最新の技術まで学べる内容でした。各演習では Inside Airbnb の San Francisco Airbnb レンタルデータセットを使用しました。
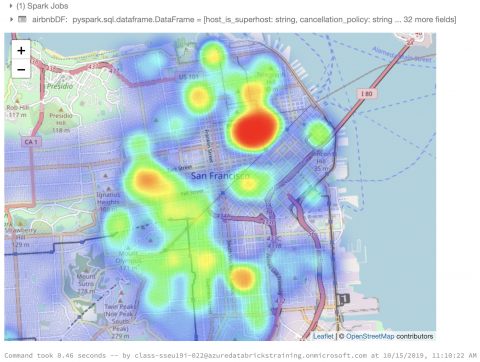
トレーニングでは、決定木やデータ入力、データサイエンスと、一般的な機械学習の概念がカバーされましたが、私は特に Spark と互換性のある OSS ツールを知ることができ、それに触れられたことが最も役に立ちました。特に、MLflow と MLeap は優れた開発ツールであることを知りました。
MLflow
MLflow は実験、再現性、展開など、機械学習に必要なライフサイクルを管理する OSS です。以前は問題を調べる際に、作成した多くのモデルと関連するパラメーターおよびメトリックを手動で追跡する必要がありました。これらの作業は時間を費やす可能性があるため、MLflow が登場しました。
MLflowは、次の3つの主要な問題に対処しようとしています。
- 実験を追跡する困難
- コードを再現する困難
- モデルをパッケージ化して展開する標準的な方法がないこと
MLflow は、MLflow 追跡、MLflow モデル、および MLflow プロジェクトの3つのコンポーネントで構成されています。 トレーニングは MLflow 追跡に重点を置いていました。MLflow 追跡は環境やライブラリに依存しない機械学習に特化したロギング API です。例えば、予測モデルを作るとします。モデルの作成には、データクリーニング、プレプロセッシング、モデルの学習、クロスバリデーションなどを順次実行する必要があります。これら一連の作業をパイプラインと呼び、このパイプラインを実際に実行することを、RUN と言います。この RUN は次の4つの対象を記録することにより、MLflow 追跡は、機械学習に必要なライフサイクル管理することができます。
RUNの記録対象
- パラメーター:ランダムフォレストモデルのツリーの数などの入力パラメーターのキーと値のペア
- 指標:RMSE や ROC 曲線下面積などの評価指標
- アーティファクト:任意の形式の出力ファイル。 例えば、画像、pickle化モデル、データファイルなど
- ソース:元のソースコード
追跡されたモデルは簡単に保存でき、必要に応じて運用環境に展開できます。 また、MLflow によりこのプロセスが標準化されたことで大幅に加速され、スケーラビリティが実現します。 MLFlow を使って行う実験は、CLI、REST からだけでなく、Python、Java や R などのライブラリを使って追跡することもできます。
MLeap
Spark はバッチ予測に優れていますが、単一行の予測にはそれほど適していません。そこで、MLeap を使うことで、Spark が苦手とする単一行の予測に対応できます。MLeap は、Spark でトレーニングされたパイプラインをシリアル化し、JVM ベースの API サーバーにデプロイし、リアルタイムの1回限りのリクエストを実行するように設計されたオープンソースの Spark パッケージです。 セッションの終わりに、Azure Databricks ノートブックをローカルにダウンロードし、持ち帰ることができました。
セッション(2日目・最終日)
今年の Spark + AI Summit のスローガンは Build.Unify.Scale でした。 会議中の共通のテーマは、データから価値を得るために直面する煩雑な作業の数々でした。 例えば、多くのソフトウェアフレームワークをつなぎ合わせる必要、信頼できないパイプラインで構築された一貫性のないデータの複数のコピーを処理することなどです。この2日間に展示されたプラットフォームは、これらの問題に対処し、データ駆動型プロセスを加速しようとするものです。
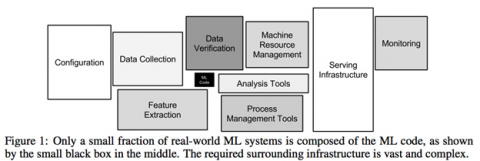
Delta Lake もそのようなプラットフォームの一つです。New Developments in the Open Source Ecosystem (オープンソースエコシステムの新しい開発)というキーノートで、Databricks のプリンシパルソフトウェアエンジニアの Michael Armbrust は、Delta Lake が Linux Foundation プロジェクトに入ることを発表しました。このプロジェクトは、コミュニティとともに、データレイクの大量のデータを管理するためのオープンスタンダードの確立を目指しています。
Delta Lake は、データレイクの信頼性とスケーラビリティの向上に重点を置いています。 ACID トランザクションを含む高いレベルの抽象化により、複雑なデータエンジニアリングアーキテクチャが、シンプルな設計になります。このプロジェクトは数千の組織に展開されており、毎月エクサバイトのデータを処理しています。
もう1つの興味深いキーノートは、AlphaStar: Mastering the Real-Time Strategy Game StarCraft II (AlphaStar:リアルタイム戦略ゲームStarCraft IIの習得)です。 修士課程でゲーム理論を学んだことがあるので、この基調講演は個人的に興味がありました。 AI がチェスで人間に勝てるようになったのち、囲碁、Star Craft などと、よりルールが複雑になったとしても、人間に勝てるようになったことを知り驚きました。 ニューラルネットワーク、強化学習によるマルチプレイ、マルチエージェント学習、模倣学習などの汎用機械学習技術を使用して、ゲームデータからモデルを直接に学習させました。AlphaStar は世界最高のプレイヤーの2人に勝っただけでなく、プロ StarCraft プレイヤーの99.8%を超えるランクスコアを維持しています。
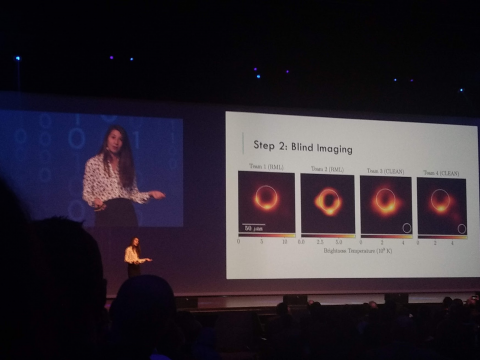
私のお気に入りのキーノートは、今年初めに史上初のブラックホールの写真を世界に発表した Caltech の計算科学と数学科学の助教授である Katie Boumanです。Imaging the Unseen: Taking the First Picture of a Black Hole (目に見えない画像を撮影する:ブラックホールの最初の写真を撮る)で、Katie はチームが Event Horizon Telescope の天空の素晴らしさを宇宙で撮影するプロセスについて話してくれました。
終わりに
あらゆる種類の巨大なデータに対し、処理を行うことが当たり前になってきました。Spark はそんな巨大なデータを扱うのに適したツールです。ソフトウェアエンジニアとデータサイエンティストが、どのように Spark を使い、様々な業界の問題解決を行っているのかを知ることは興味深いものでした。このカンファレンスに出席し、データ処理のバイプライン設計について色々と学ぶことができました。まだまだ知らないフレームワークなど多々ありますが、これからも学び続けていきたいと思います。
INFORMATION
KandaSearch
KandaSearch はクラウド型企業向け検索エンジンサービスです。
オープンAPIでカスタマイズが自由にできます。
セミナー
企業が検索エンジンを選定する際のポイントから、
実際の導入デモをお客様ご自身でご体験!