INFORMATION
テクノロジ
Solrの日本語対応 -新しく追加されたトークナイザ・トークンフィルタ-
先日、Lucene/Solrのbranch_3x(3.6)とtrunk(4.0)にコミットされた日本語向けのトークナイザ・トークンフィルタをご紹介します。
LuceneのJIRAのチケット LUCENE-3305 にて、日本語形態素解析器Kuromojiが導入されました。
これにより、日本語ドキュメントに対して形態素解析に基づく単語分割が可能になります。
従来、Lucene/Solrで日本語対応をする場合は、lucene-gosenやSenを使用する方法などをとってきましたが、今回の対応であらかじめLucene/Solrに組み込まれたものを使用するということが可能になります。
また一方で、LUCENE-2906にて、CJK文字に関するトークンフィルタも追加されました。
本記事では、これらのトークナイザ・トークンフィルタに関して、2012/2/23時点のソースに基づいて調査したものを解説いたします。
Solrでの定義例:
mode: ”normal”、”search”、”extended”のいずれかを指定します。デフォルトは”search”です。
user-dictionary: ユーザ辞書の定義ファイルを指定します。
user-dictionary-encoding: 定義ファイルのエンコードを指定します。
解説:
・辞書は、mecab用IPA辞書mecab-ipadicを使用しています。
Lucene側でmecab-NAIST-jdicに変更することが可能です。
・mode詳細
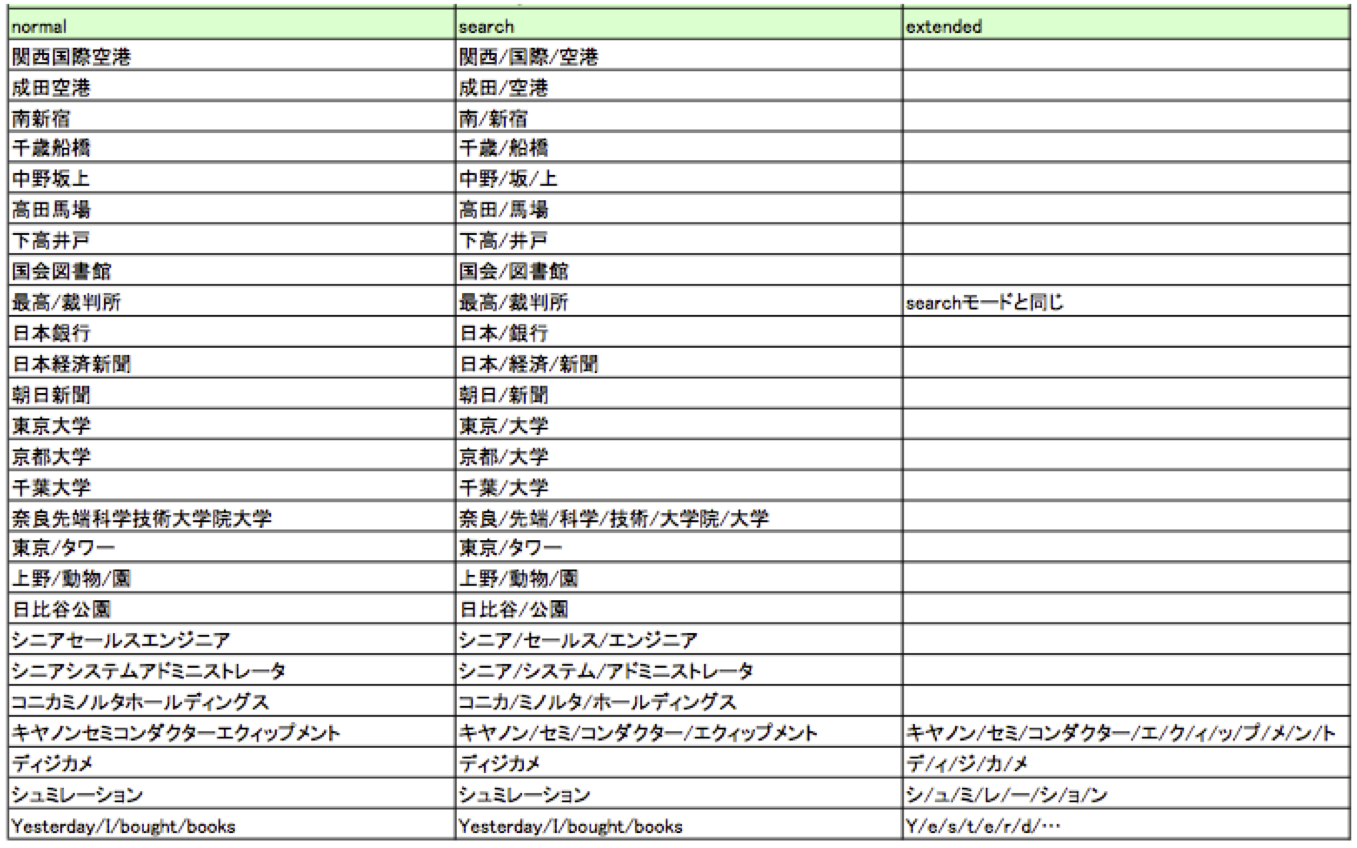
normal:形態素解析による通常の単語分割を行います。
search:複合語で構成された単語を細かく分割します。
例えば「関西国際空港」という固有名詞を「関西」「国際」「空港」に分割します。
「国際」や「空港」で「関西国際空港」をヒットすることができるようになります。
extended :searchモードの処理をしつつ、追加で、辞書にない未知語を1-gramに分割します。
例えば「ディジカメ」という未知語をデ/ィ/ジ/カ/メに分割します。
未知語の検索漏れを防ぎます。
・mode別の出力例です。
・ユーザ辞書
ユーザ辞書はSolrホームディレクトリのconfに配置します。Solr起動時に読み込まれます。
デフォルト辞書にない新語・人名などを登録することができます。
CSV形式で、単語, 単語分割表現, よみがな, 品詞名を登録します。
ユーザ辞書登録されている単語は優先的に単語分割されます。

・その他
・Lucene側に形態素解析の様子を視覚化するメソッドが用意されています。(例:最高裁判所)
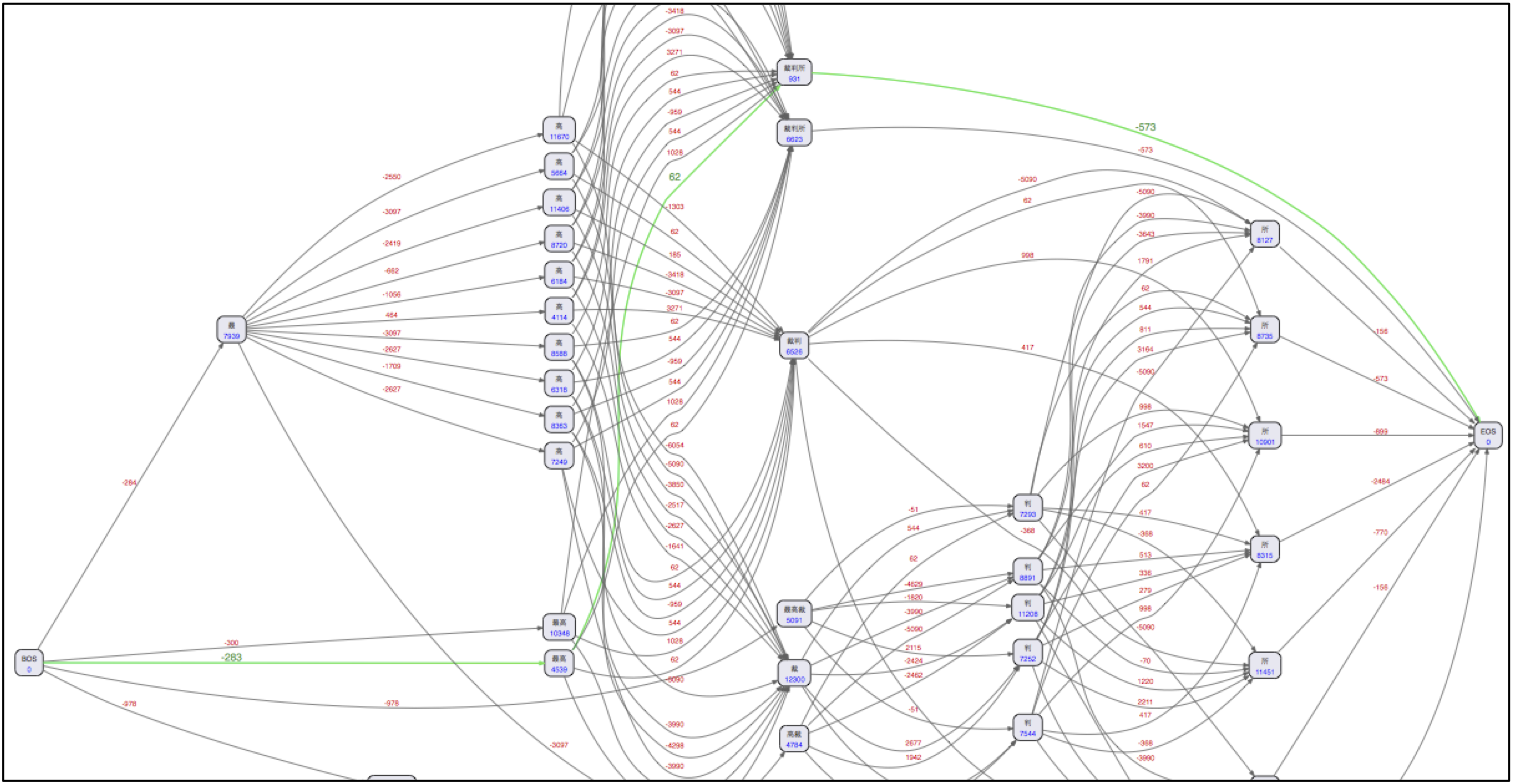
・トークナイズの処理では、経路コスト・連結コスト・単語コストを算出し、最も低いコストを選択して
単語分割が処理されます。searchモードでは、漢字3文字以上、それ以外の文字8文字以上でペナルティ
コストを加算しています。この調整の結果、短い単語での分割ができます。
・ユーザ辞書登録されている単語のコスト値は、低く設定されているため、優先的に単語分割されます。
・現時点でオープンしているチケット LUCENE-3767 があります。形態素解析の計算ロジックの改修と
searchモードの改良があるためこれがコミットされると結果が若干変わることが想定されます。
Solrでの定義例:
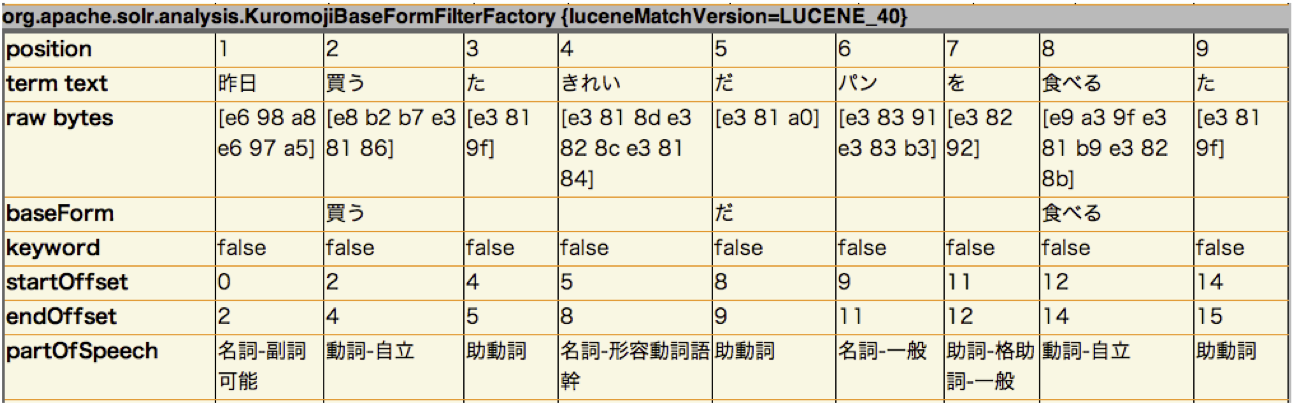
出力例: 昨日買ったきれいなパンを食べた
Solrでの定義例:
tags: 除外対象品詞の設定ファイルを指定します。
enablePositionIncrements:取り除いたストップワードの位置増分情報を有効にする(true)か
否か(false)を指定します。
解説:
・設定ファイルはSolrホームディレクトリのconf/lang/stoptags_ja.txtに配置されています。

・出力例: 昨日買ったきれいなパンを食べた
(例では、助動詞が除外対象品詞になっています)

Solrでの定義例:
出力例: 54321SOLRハンカクカタカナ

Solrでの定義例:
出力例: Hello, 日本人です。

する方法と、N-Gramでは、Lucene/Solrに付属のCJKTokenizerを利用する方法がありました。
今回の新しく追加されたトークナイザ・フィルタとの比較をすると次のようになります。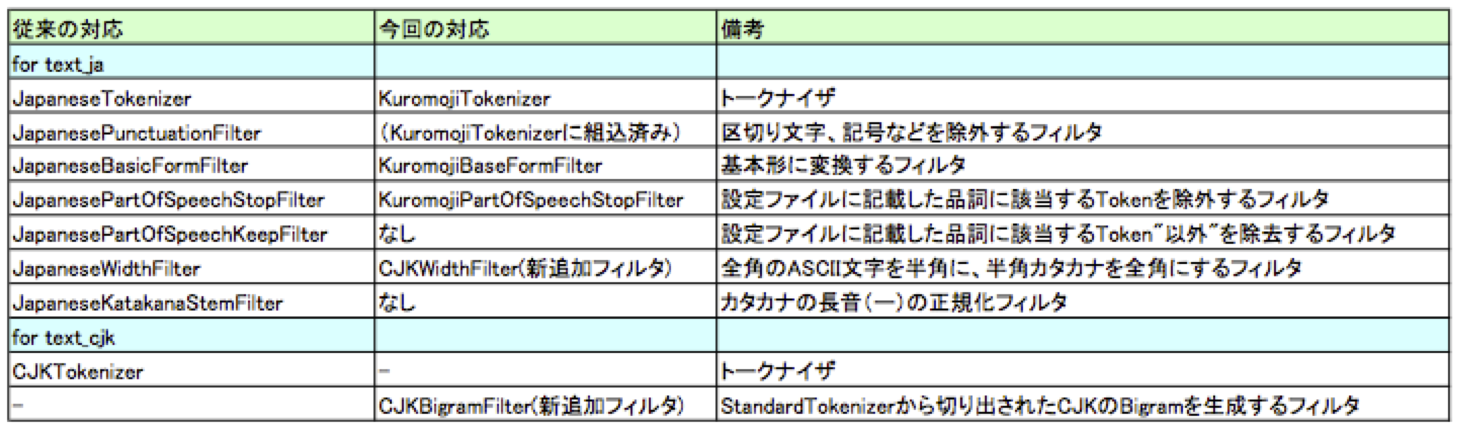
同じ機能を有するトークナイザやフィルタがありますが、ないものもあることがわかります。
なお、JapaneseTokenizerには単語を品詞により合成することができるcompositePOS属性を持って
いますが、KuromojiTokenizerにはその機能は持っていません。
また、JapaneseKatakanaStemFilterは、Kuromoji側と組み合わせて併用するということも考えられます。

・ カスタム辞書の取り扱い
lucene-gosen:
カスタム辞書のCSVを追加して辞書のビルドを行い、jarファイルを再配置します。
Kuromoji:
カスタム辞書のCSVをSolrホームディレクトリのconfに配置して、Solrを再起動します。
単語のコスト値を入力できません(決め打ちになっています)。
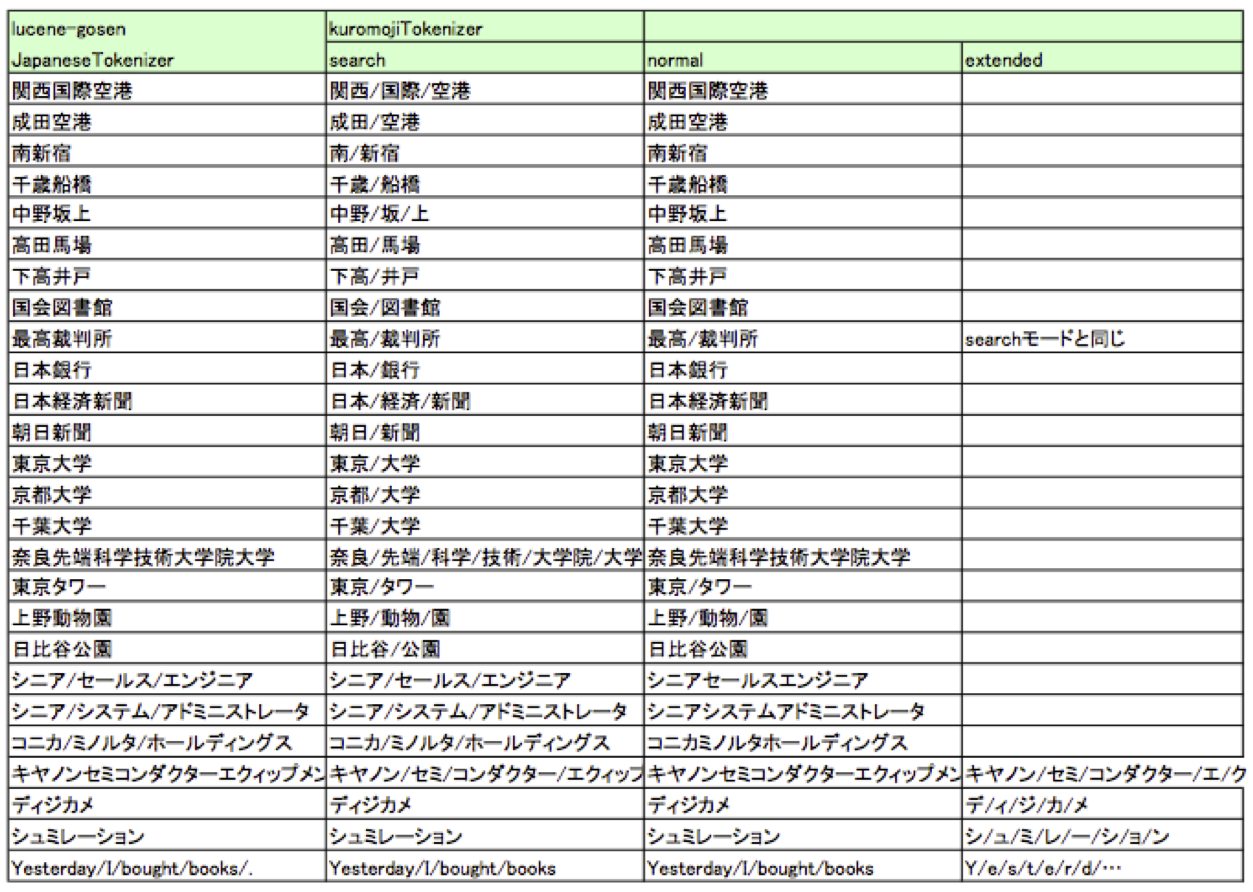
JapaneseTokenizerでは固有名詞はそのまま切り出しますが、KuromojiTokenizerのsearchモードでは
複合語の単語分割がより促されていることがわかります。
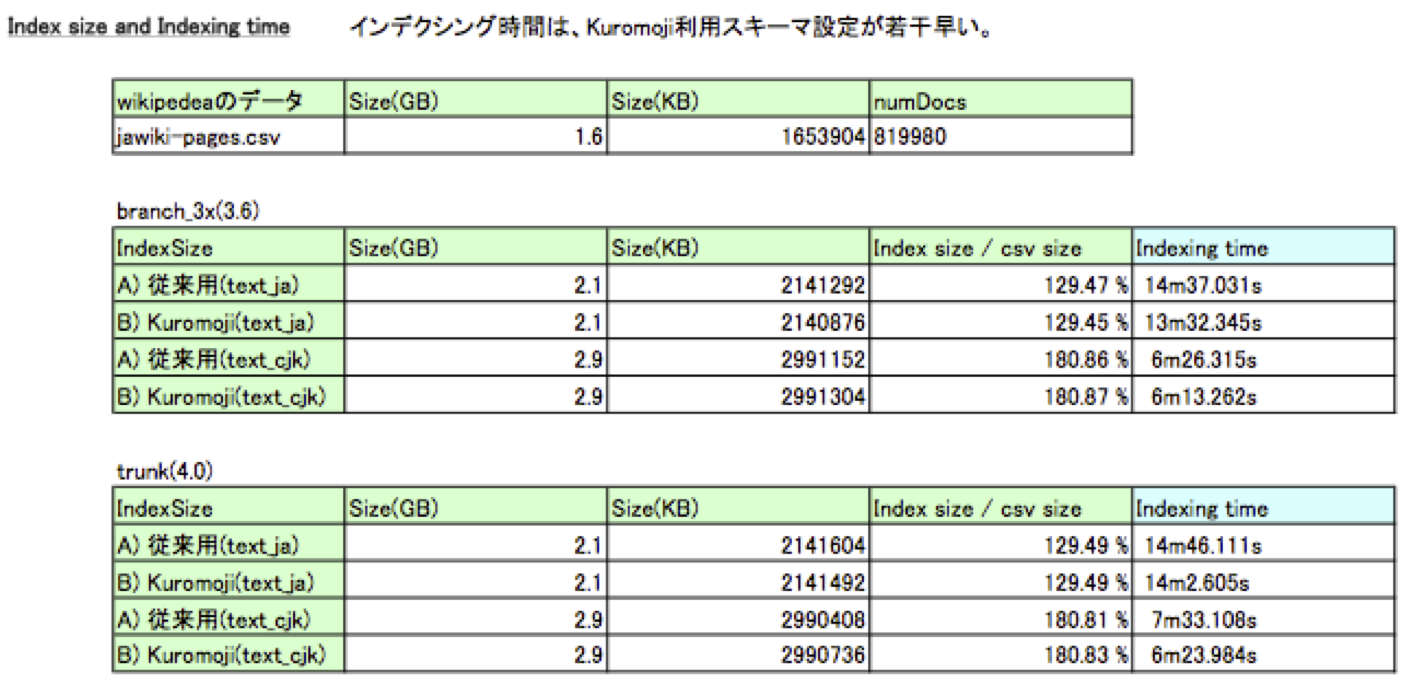
Wikipediaデータ約82万件をインデクシングし、その時間を計測しました。
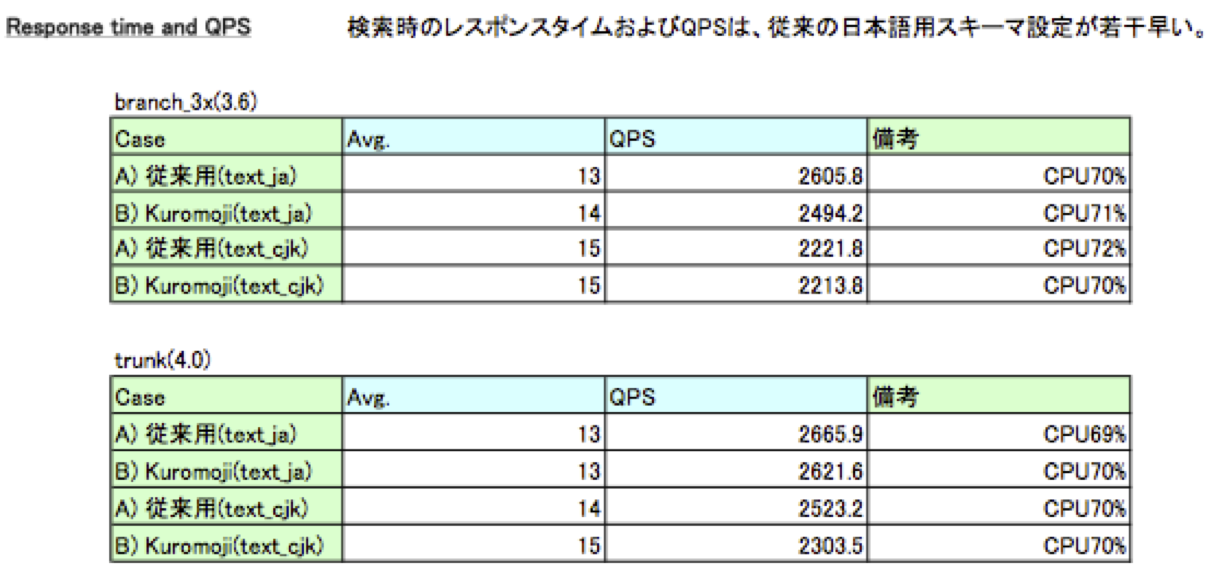
また検索時のレスポンスタイムおよびQPSを計測しました。
A)従来の日本語用スキーマ
text_jaのフィールドタイプは、Solrに組込済みのtext_jaのKuromoji用設定をlucene-gosen用クラス
に置き換えて設定しています。
text_cjkのフィールドタイプは、従来のCJKTokenizerを利用し、半角カタカナの全角変換は
MappingCharFilterを利用しています。

B) Kuromoji利用スキーマ
text_jaとtext_cjkのフィールドタイプはそれぞれ、Solrのbranch_3x/trunkに
内包されている設定を利用しています。

ID、タイトル、本文のフィールドからなるデータをWikipediaデータからロードしてインデックスを
作成し、text_jaフィールドタイプでのインデクシングと、text_cjkフィールドタイプでの
インデクシングをそれぞれ行っています。
そして、クライアントからJMeterを使って検索リクエストを発行します。検索する文字列は、
弊社のサブスクリプション・パッケージ付属の重要語抽出機能を用いて抽出したフレーズを
用いています。Solrは、ヒープサイズを1024MBにして起動し、CPUの消費を平均70-80%に
なるようにクライアントのJMeterスレッド数を調整して負荷がけを行い、平均レスポンスタイムと
QPSを計測しました。
・レスポンスタイム(Avg.)およびQPS
結果としては、従来の日本語用スキーマ設定とKuromoji利用スキーマ設定で、
多少の差異はありますがそれほど大きな違いがないということがわかりました。
今回新しく追加されたトークナイザやフィルタは、Solrの日本語対応として利用されることが
今後増えるであろうという印象を持ちました。
特にKuromojiTokenizerのsearchモードは、検索漏れをカバーしうる単語分割をしますので、
適用されるケースが増えていくものと思われます。
今後も改良が進められると思いますので推移を見守るのがよいかと思います。
LuceneのJIRAのチケット LUCENE-3305 にて、日本語形態素解析器Kuromojiが導入されました。
これにより、日本語ドキュメントに対して形態素解析に基づく単語分割が可能になります。
従来、Lucene/Solrで日本語対応をする場合は、lucene-gosenやSenを使用する方法などをとってきましたが、今回の対応であらかじめLucene/Solrに組み込まれたものを使用するということが可能になります。
また一方で、LUCENE-2906にて、CJK文字に関するトークンフィルタも追加されました。
本記事では、これらのトークナイザ・トークンフィルタに関して、2012/2/23時点のソースに基づいて調査したものを解説いたします。
新しく追加されたトークナイザ・トークンフィルタ
KuromojiTokenizer
日本語形態素解析器Kuromojiで単語分割するトークナイザです。Solrでの定義例:
<fieldType name="text_ja" class="solr.TextField" positionIncrementGap="100">
<analyzer>
<tokenizer class="solr.KuromojiTokenizerFactory" mode="search"
user-dictionary="userdict.txt" user-dictionary-encoding="UTF-8"/>
:
属性: mode: ”normal”、”search”、”extended”のいずれかを指定します。デフォルトは”search”です。
user-dictionary: ユーザ辞書の定義ファイルを指定します。
user-dictionary-encoding: 定義ファイルのエンコードを指定します。
解説:
・辞書は、mecab用IPA辞書mecab-ipadicを使用しています。
Lucene側でmecab-NAIST-jdicに変更することが可能です。
・mode詳細
normal:形態素解析による通常の単語分割を行います。
search:複合語で構成された単語を細かく分割します。
例えば「関西国際空港」という固有名詞を「関西」「国際」「空港」に分割します。
「国際」や「空港」で「関西国際空港」をヒットすることができるようになります。
extended :searchモードの処理をしつつ、追加で、辞書にない未知語を1-gramに分割します。
例えば「ディジカメ」という未知語をデ/ィ/ジ/カ/メに分割します。
未知語の検索漏れを防ぎます。
・mode別の出力例です。
・ユーザ辞書
ユーザ辞書はSolrホームディレクトリのconfに配置します。Solr起動時に読み込まれます。
デフォルト辞書にない新語・人名などを登録することができます。
CSV形式で、単語, 単語分割表現, よみがな, 品詞名を登録します。
ユーザ辞書登録されている単語は優先的に単語分割されます。
・その他
・Lucene側に形態素解析の様子を視覚化するメソッドが用意されています。(例:最高裁判所)
・トークナイズの処理では、経路コスト・連結コスト・単語コストを算出し、最も低いコストを選択して
単語分割が処理されます。searchモードでは、漢字3文字以上、それ以外の文字8文字以上でペナルティ
コストを加算しています。この調整の結果、短い単語での分割ができます。
・ユーザ辞書登録されている単語のコスト値は、低く設定されているため、優先的に単語分割されます。
・現時点でオープンしているチケット LUCENE-3767 があります。形態素解析の計算ロジックの改修と
searchモードの改良があるためこれがコミットされると結果が若干変わることが想定されます。
KuromojiBaseFormFilter
辞書の基本形に変換するフィルタです。Solrでの定義例:
<fieldType name="text_ja" class="solr.TextField" positionIncrementGap="100">
<analyzer>
<tokenizer class="solr.KuromojiTokenizerFactory" mode="search"/>
<filter class="solr.KuromojiBaseFormFilterFactory"/>
:
属性: なし出力例: 昨日買ったきれいなパンを食べた
KuromojiPartOfSpeechStopFilter
設定ファイルに記載した品詞に該当するTokenを除外するフィルタです。Solrでの定義例:
<fieldType name="text_ja" class="solr.TextField" positionIncrementGap="100">
<analyzer>
<tokenizer class="solr.KuromojiTokenizerFactory" mode="search"/>
<filter class="solr.KuromojiBaseFormFilterFactory"/>
<filter class="solr.KuromojiPartOfSpeechStopFilterFactory"
tags="lang/stoptags_ja.txt" enablePositionIncrements="true"/>
:
属性: tags: 除外対象品詞の設定ファイルを指定します。
enablePositionIncrements:取り除いたストップワードの位置増分情報を有効にする(true)か
否か(false)を指定します。
解説:
・設定ファイルはSolrホームディレクトリのconf/lang/stoptags_ja.txtに配置されています。
・出力例: 昨日買ったきれいなパンを食べた
(例では、助動詞が除外対象品詞になっています)
CJKWidthFilter
全角のASCII文字を半角に、半角カタカナを全角にするフィルタです。Solrでの定義例:
<fieldType name="text_ja" class="solr.TextField" positionIncrementGap="100">
<analyzer>
<tokenizer class="solr.KuromojiTokenizerFactory" mode="search"/>
<filter class="solr.CJKWidthFilterFactory"/>
:
属性: なし出力例: 54321SOLRハンカクカタカナ
CJKBigramFilter
StandardTokenizerまたはICUTokenizer から生成されたCJK文字のBigramを生成するフィルタです。Solrでの定義例:
<fieldType name="text_cjk" class="solr.TextField" positionIncrementGap="100">
<analyzer>
<tokenizer class="solr.StandardTokenizer"/>
<filter class="solr.CJKBigramFilter"/>
:
属性: なし出力例: Hello, 日本人です。
従来の日本語対応との比較
従来の日本語対応としては主に、形態素解析では、lucene-gosenのJapaneseTokenizerや各種Filterを利用する方法と、N-Gramでは、Lucene/Solrに付属のCJKTokenizerを利用する方法がありました。
今回の新しく追加されたトークナイザ・フィルタとの比較をすると次のようになります。
文字列処理クラスの対比
同じ機能を有するトークナイザやフィルタがありますが、ないものもあることがわかります。
なお、JapaneseTokenizerには単語を品詞により合成することができるcompositePOS属性を持って
いますが、KuromojiTokenizerにはその機能は持っていません。
また、JapaneseKatakanaStemFilterは、Kuromoji側と組み合わせて併用するということも考えられます。
使用する辞書に関する対比
・ 対応する辞書・ カスタム辞書の取り扱い
lucene-gosen:
カスタム辞書のCSVを追加して辞書のビルドを行い、jarファイルを再配置します。
Kuromoji:
カスタム辞書のCSVをSolrホームディレクトリのconfに配置して、Solrを再起動します。
単語のコスト値を入力できません(決め打ちになっています)。
JapaneseTokenizerとKuromojiTokenizerのトークナイズの対比
JapaneseTokenizerでは固有名詞はそのまま切り出しますが、KuromojiTokenizerのsearchモードでは
複合語の単語分割がより促されていることがわかります。
インデクシングや検索の処理速度に関する対比
従来の日本語用スキーマ設定とKuromoji利用スキーマ設定でWikipediaデータ約82万件をインデクシングし、その時間を計測しました。
また検索時のレスポンスタイムおよびQPSを計測しました。
A)従来の日本語用スキーマ
text_jaのフィールドタイプは、Solrに組込済みのtext_jaのKuromoji用設定をlucene-gosen用クラス
に置き換えて設定しています。
text_cjkのフィールドタイプは、従来のCJKTokenizerを利用し、半角カタカナの全角変換は
MappingCharFilterを利用しています。
B) Kuromoji利用スキーマ
text_jaとtext_cjkのフィールドタイプはそれぞれ、Solrのbranch_3x/trunkに
内包されている設定を利用しています。
ID、タイトル、本文のフィールドからなるデータをWikipediaデータからロードしてインデックスを
作成し、text_jaフィールドタイプでのインデクシングと、text_cjkフィールドタイプでの
インデクシングをそれぞれ行っています。
そして、クライアントからJMeterを使って検索リクエストを発行します。検索する文字列は、
弊社のサブスクリプション・パッケージ付属の重要語抽出機能を用いて抽出したフレーズを
用いています。Solrは、ヒープサイズを1024MBにして起動し、CPUの消費を平均70-80%に
なるようにクライアントのJMeterスレッド数を調整して負荷がけを行い、平均レスポンスタイムと
QPSを計測しました。
計測結果
・インデクシング時間・レスポンスタイム(Avg.)およびQPS
結果としては、従来の日本語用スキーマ設定とKuromoji利用スキーマ設定で、
多少の差異はありますがそれほど大きな違いがないということがわかりました。
今回新しく追加されたトークナイザやフィルタは、Solrの日本語対応として利用されることが
今後増えるであろうという印象を持ちました。
特にKuromojiTokenizerのsearchモードは、検索漏れをカバーしうる単語分割をしますので、
適用されるケースが増えていくものと思われます。
今後も改良が進められると思いますので推移を見守るのがよいかと思います。
INFORMATION
KandaSearch
KandaSearch はクラウド型企業向け検索エンジンサービスです。
オープンAPIでカスタマイズが自由にできます。
セミナー
企業が検索エンジンを選定する際のポイントから、
実際の導入デモをお客様ご自身でご体験!