INFORMATION
テクノロジ
ApacheCon North America 2018に参加してきました(3日目、4日目)
溝口 泰史 著
前回に続き、ApacheCon North America 2018(以下、ACNA2018)の3日目と4日目のレポートです。
2018/9/26(3日目)
Streaming Media at Scale – The Story of How Apache Traffic Control Came To Be
Apache Traffic Controlというプロジェクトは、Comcast社がASFにコントリビュートした、CDNの機能を提供するソフトウェアであるということで、元々はComcast社がSamsung社と提携した際にCDNが必要になり、そのために内製したソフトが元になっているとのことです。
Traffic Controlの機能について簡単に触れられてはいたものの、なぜASFを寄贈先に選んだのかというところが講演の焦点となっており、
(インフラチームが存在し、CI/CD基盤があり、メーリングリストが存在する)
の3点をASFを寄贈先に選んだ理由として挙げていました。
 近年ではGithubなどで企業も個人も気軽にOSSを公開できるようになりましたが、OSSのメリットを享受しつつ開発を継続していく場合に、コードをどこに寄贈するかの選定を行うと言う話は(そんな大規模な内製コードをOSSにすると言う経験はないので)とても新鮮に感じました。
近年ではGithubなどで企業も個人も気軽にOSSを公開できるようになりましたが、OSSのメリットを享受しつつ開発を継続していく場合に、コードをどこに寄贈するかの選定を行うと言う話は(そんな大規模な内製コードをOSSにすると言う経験はないので)とても新鮮に感じました。
Spatial index optimization and GIS query support on Druid using Apache Lucene
SK Telecom社のエンジニアによる、地理検索のためにDruidからLuceneの機能を呼び出せるようにしたというセッションで、Luceneがどのように利用されているのかが知りたくて参加しました。
Druidというプロジェクトはあまりよく知らなかったのですが、リアルタイムの時系列データを収集・検索できるデータベースとのことで、SK Telecom社ではユーザーの位置情報と通信状況などを収集し、分析するために利用しているが、Druid単体では地理データを処理することができず、地理データを処理するシステムをつなぎ合わせて運用しており、それがLuceneの機能を統合するモチベーションになったといういうことでした。
 コードが多く出てきたものの、黒背景のIDEのスクリーンショットであったのと、一部分だけが切り取られていたため、どういう処理か詳しく確認することはできなかったものの、同じASFのプロジェクト同士でコラボレーションが行いやすいというのは、多くのプロジェクトを擁し、ライセンスに関する懸念が少ないということの強みであると感じました。
コードが多く出てきたものの、黒背景のIDEのスクリーンショットであったのと、一部分だけが切り取られていたため、どういう処理か詳しく確認することはできなかったものの、同じASFのプロジェクト同士でコラボレーションが行いやすいというのは、多くのプロジェクトを擁し、ライセンスに関する懸念が少ないということの強みであると感じました。
Scaling Apache Spark for data pipelines and intelligent systems at Uber
UberがどのようにSparkを利用しているかについてのセッションでした。 Uberは初日、二日目のレポートの冒頭の空港にあった看板の画像にある通り、配車サービスの代名詞となっており、機械学習を多用していることで有名です。現時点でSparkをSpark as a Serviceとして利用できる環境を構築しているとのことで、機械学習で何をしているかと言うセッションでした。 Sparkを呼び出すRとJupyterのインターフェースを提供しており、それらを使ってデータアナリストは、サービスの安全性、レストランのリコメンデーション、サポートのための自然言語処理、ドライバーのリスクチェックを行なっているとのことでした。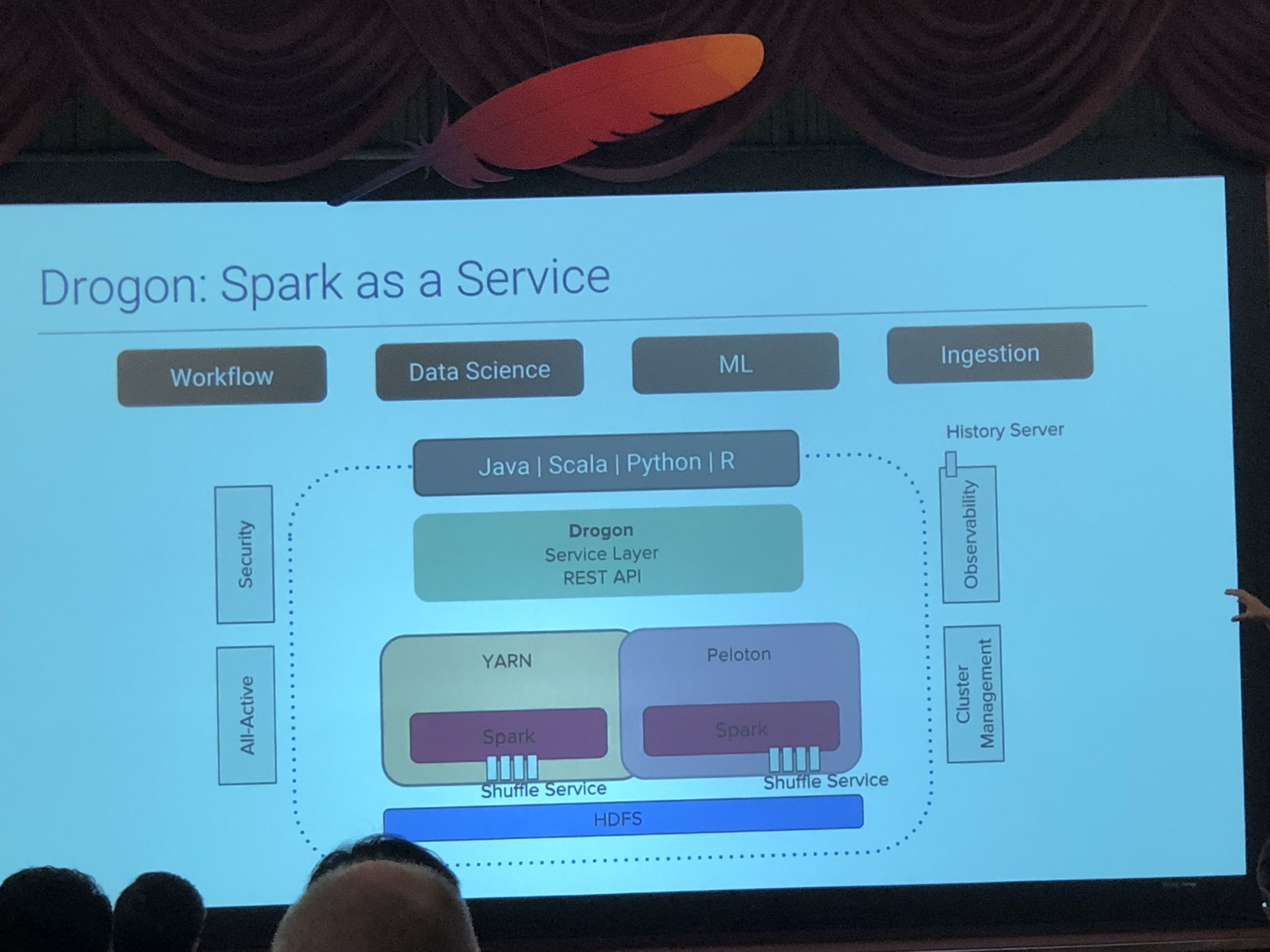 社内で多くのSpark環境を立てているだけあり、Spark自体を改善してコミュニティに成果を還元しており、特に膨大なデータを解析する必要からスケールに関する改善を行なっているが、社内にはSparkの内部フォークや独自プラグインがまだ存在するとのことで、最終的には公式でそれらの機能を取り込むように働きかけ、最終的には公式の最新版のみを社内で利用できるようにしたいと言っていたのが印象的でした。
社内で多くのSpark環境を立てているだけあり、Spark自体を改善してコミュニティに成果を還元しており、特に膨大なデータを解析する必要からスケールに関する改善を行なっているが、社内にはSparkの内部フォークや独自プラグインがまだ存在するとのことで、最終的には公式でそれらの機能を取り込むように働きかけ、最終的には公式の最新版のみを社内で利用できるようにしたいと言っていたのが印象的でした。2日目のMicrosoftのセッションでも少し触れられていましたが、OSSを利用する際に自身の利用目的に適うように改修をすると、そのメンテナンスに手間がかかる言うことを直接的ではありませんが感じることができました。
また、このセッションで触れられていた解析対象の中で個人的に何よりも面白かったのは、Sparkが動作するJVMのメトリック情報自体でした。確かにJVMのチューニングで数パーセントでもパフォーマンスが向上すれば、成果物をビジネスに反映する時間の短縮にも、成果物を産出するための資源の節約にも繋がるため納得感はありましたが、機械学習を取り入れている企業があらゆる側面でデータ処理の最適化を進めていることが強く感じられました。
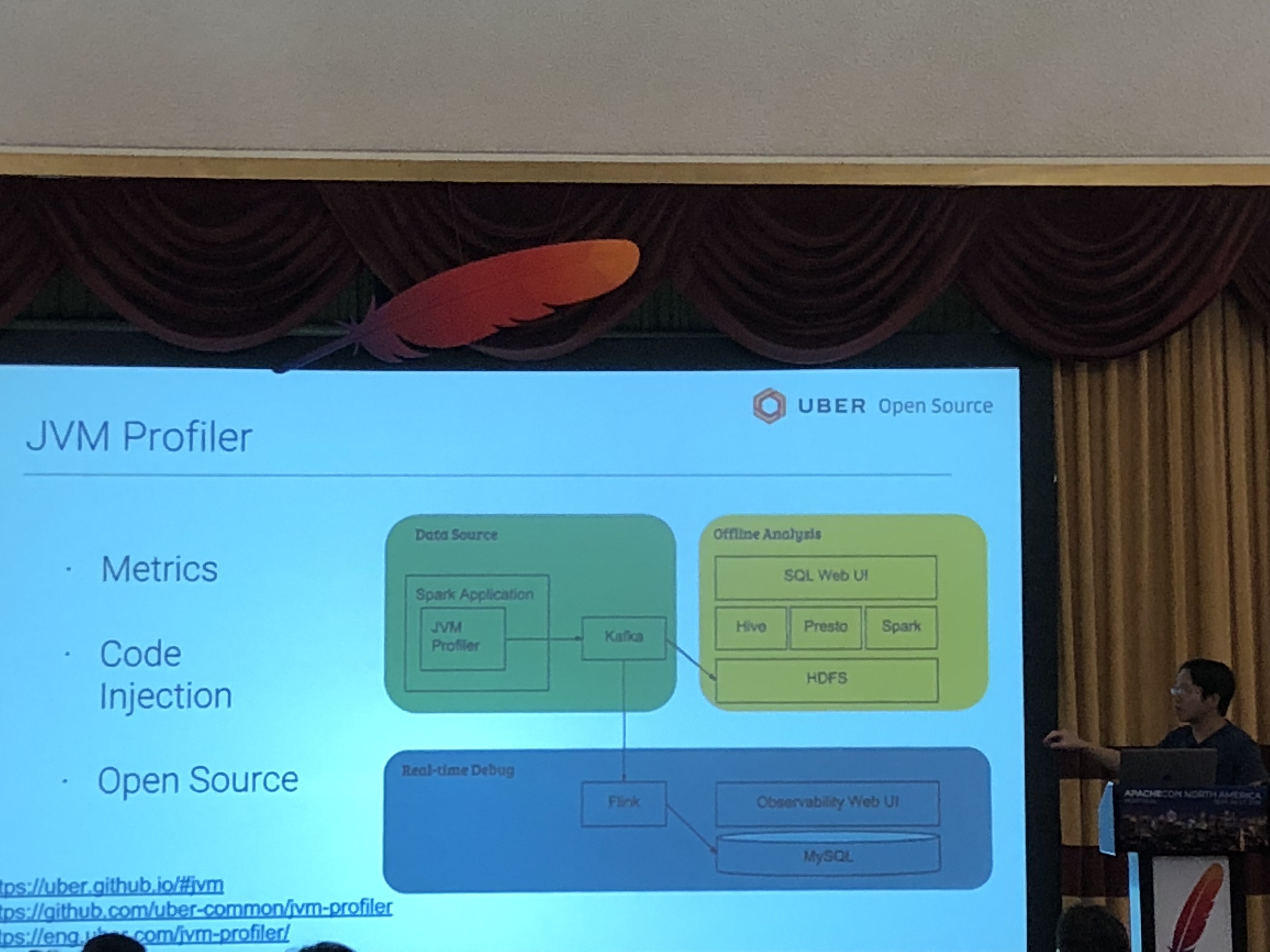
2018/9/27(4日目、最終日)
From content to search: Speed-dating Apache Solr
Solrのセッションだったため、参加しました。
セッションで利用したデータはここにあります。
内容としては、基本的なセットアップで検索サービスを作り、その仕組みを説明しつつ、シナリオに従ってその性能を改善していくと言うもので、Solrの基礎の基礎と言った感じでした。
 面白かったのはQAの方で、
面白かったのはQAの方で、
-> UpdateRequestProcessorを利用して、リンクの数をカウントする
->両方ともLuceneの上で稼働するソフトウェアで、Frienemy(Friend & Enemy)
->扱うドキュメントによる
https://apachecon.dukecon.org/acna/2018/#/scheduledEvent/c842a3629aa83867a
 OpenNLPを利用してチャットボットを作ると言うセッションで、コンポーネントの中にSolrがあったために参加しました。また、最近弊社のトレーニングを受講される方でチャットボットを作りたいと言う要望が多くあり、Solr+OpenNLPでチャットボットを作るためのノウハウを知るためでもありました。
OpenNLPを利用してチャットボットを作ると言うセッションで、コンポーネントの中にSolrがあったために参加しました。また、最近弊社のトレーニングを受講される方でチャットボットを作りたいと言う要望が多くあり、Solr+OpenNLPでチャットボットを作るためのノウハウを知るためでもありました。
チャットボットは質問と回答が異なるため、検索エンジンだけでは適切な回答を返すのは難しいと考えています。精度の改善のために機械学習等で質問文を分類すると言うアプローチがあったりするのですが、このセッションでは機械学習を利用するのではなく、あらかじめ質疑応答の文章をDiscourse Tree(対話ツリー)として構造を解析して登録し、ユーザーからの未知の質問をDiscourse Treeとして展開し、似たような構造を持つ質問に結びついているフレーズを組み合わせて回答を作ると言うものでした。
対話構造は言語に依存するため、セッションが終わった後に発表者に発表内容は日本語で実現できるか尋ねましたが、日本語用の対話解析器が必要とのことで、まだ日本語での実現は難しそうだと思いました。
また、もう一つ、Solrはどこで使われているのかがわからなかったのですが、こちらは次のセッションが始まってしまったために質問ができませんでした。
ACNA2018では、多くの新しいASFのプロジェクトの紹介、大規模なプロジェクトの事例、そしてASFのコミュニティ運営に関して多くの知識を得ることができました。
得られた知識を業務に活かせるように努めていきたいと思います。
INFORMATION
KandaSearch
KandaSearch はクラウド型企業向け検索エンジンサービスです。
オープンAPIでカスタマイズが自由にできます。
セミナー
企業が検索エンジンを選定する際のポイントから、
実際の導入デモをお客様ご自身でご体験!