INFORMATION
テクノロジ
Apache ManifoldCF -Webサーバのクロール-
今回はApache ManifoldCFのWebサーバのクロールをご説明します。
ManifoldCFの管理画面から設定を行い、実際にクロールを実行して動作を確認します。
企業内のWebサーバで情報共有している社内ポータルの検索や社内管理文書を検索する、といったケースにManifoldCFを使うことができます。Solrと連携してWebのドキュメントの検索を行います。
そして、ジョブで各種項目を設定し、実行することでクロールが実行されます。
今回は、各コネクタを次のように設定します。
WindowsサーバをクロールしてデータをSolrに渡すという流れです。
1. ManifoldCFの管理画面を表示します。
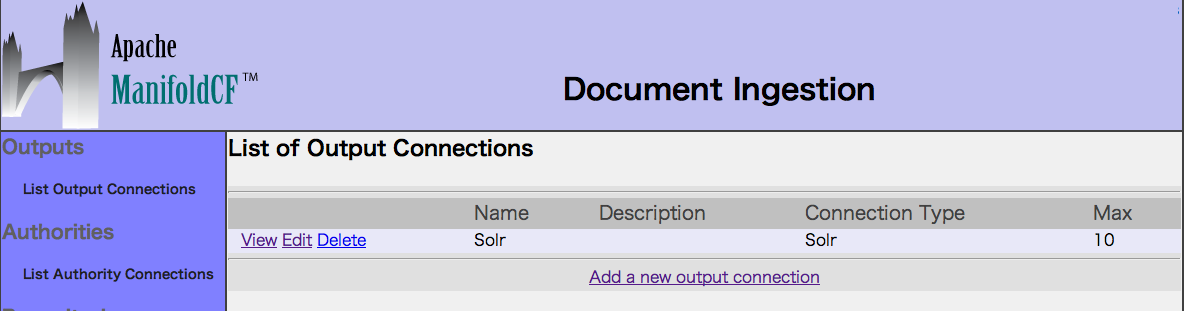
2. List Output Connectionsを選択し、コネクションをAddします。
Nameに「Solr」(任意)を入力し、Typeに「Solr」を選択します。
Continueボタンを押してSolrに関する詳細設定が表示されますが
デフォルトのままで動作するので、変更しません。
最後にSaveボタンを押します。
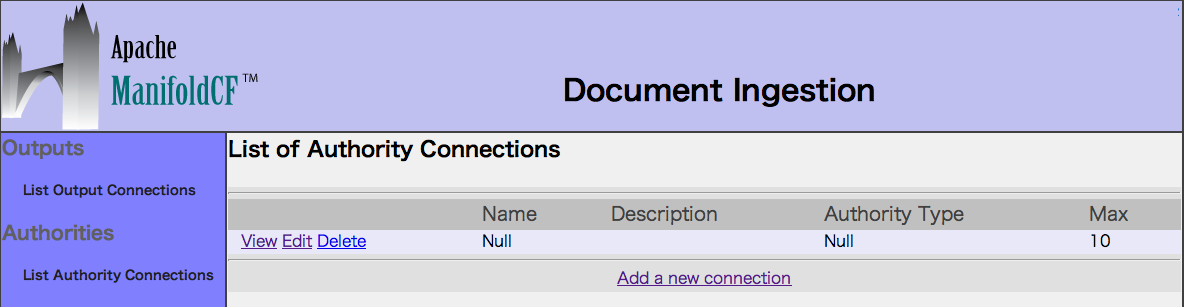
3. List Authority Connectionsを選択し、コネクションをAddします。
Nameに「Null」(任意)を入力し、Typeに「Null」を選択します。
最後にSaveボタンを押します。
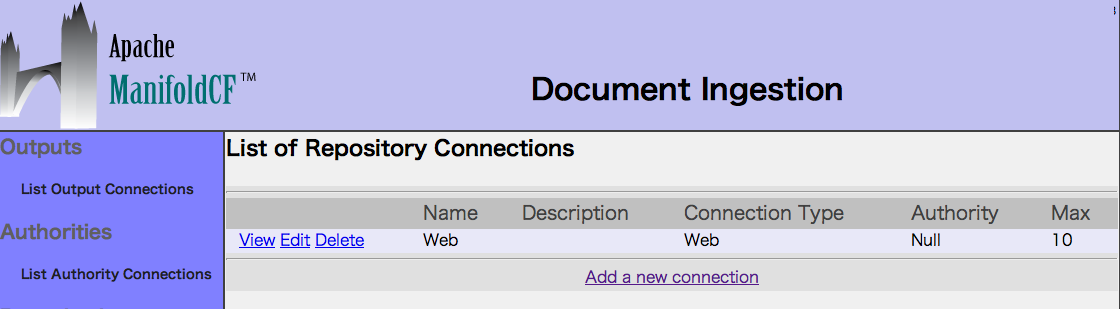
4. List Repository Connectionsを選択し、コネクションをAddします。
Nameに「Web」(任意)を入力し、
Typeに「Web」を選択し、Authorityに「Null」を選択します。
Emailタブで、メールアドレスを入力します。
最後にSaveボタンを押します。
5. List all Jobsを選択し、ジョブをAddします。
Connectionタブで、登録済みコネクションを指定します。
Outputに「Solr」、Repositoryに「Web」を選択します。
Continueボタンを押してジョブに関する詳細設定が表示されます。
Seedsタブでクロール対象の起点となるURLを入力します。
Inclusionsタブでクロール対象のURL等を入力します。
Exclusionsタブでクロール除外対象のURL等を入力します。
最後にSaveボタンを押します。
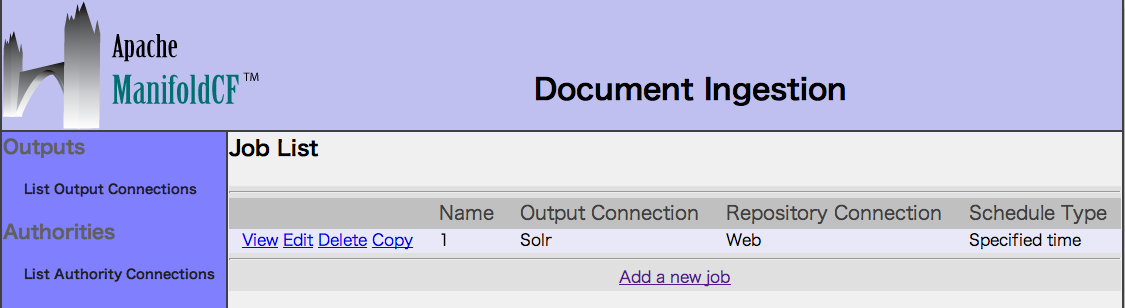
6. Status and Job Managementを選択します。
登録済みジョブのStartをクリックして、クロールを実行します。
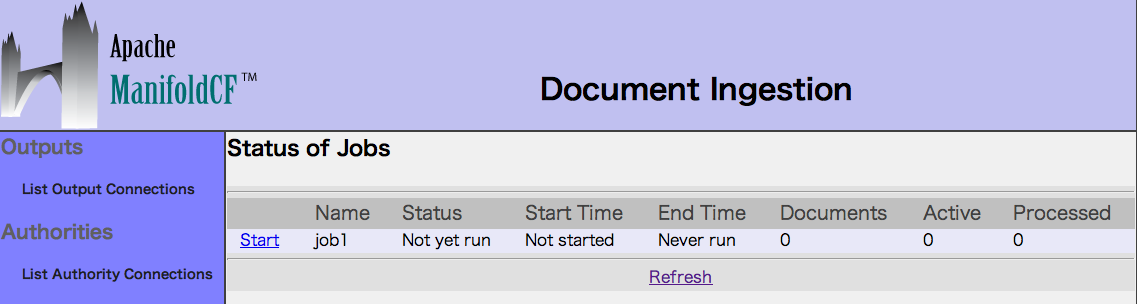
Refreshをクリックするとでジョブの経過を確認することができます。
ステータスにDoneが表示されるとクロールのジョブが終了したことになります。
7. SimpleHistoryを選択します。
レポジトリを選択してContinueボタンを押します。
ジョブの開始終了、リンクおよびドキュメントのアクセスとSolrへの投入状況など
クロール履歴を確認することができます。
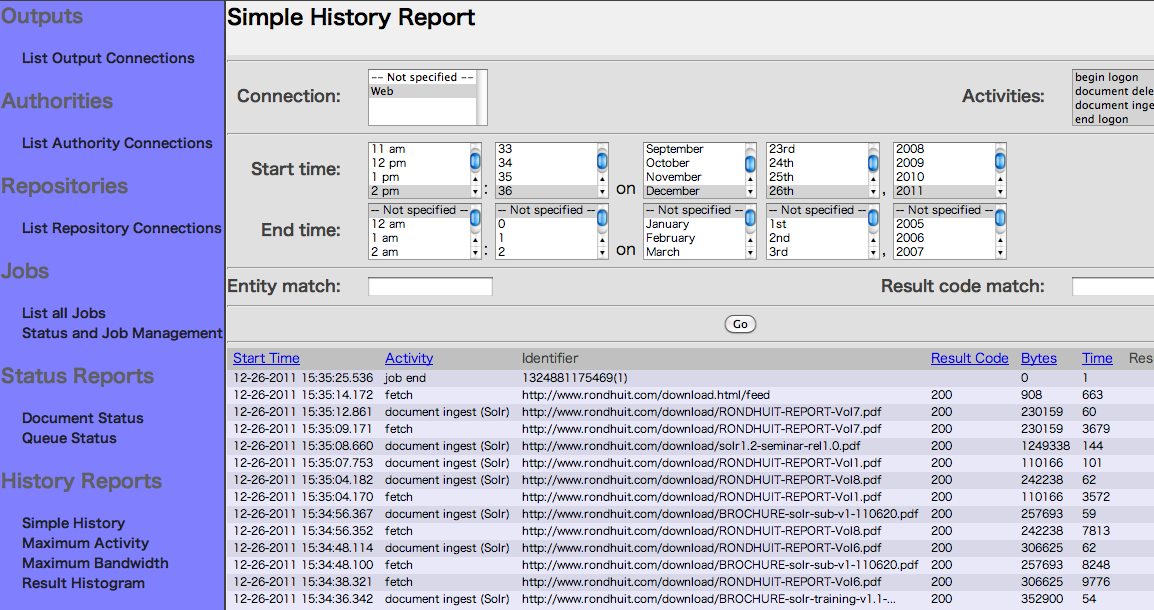
すでに前述までの過程でインデクシングが完了しています。
ここでは、検索を行って内容を確認します。
1. Solrの管理画面を表示します。
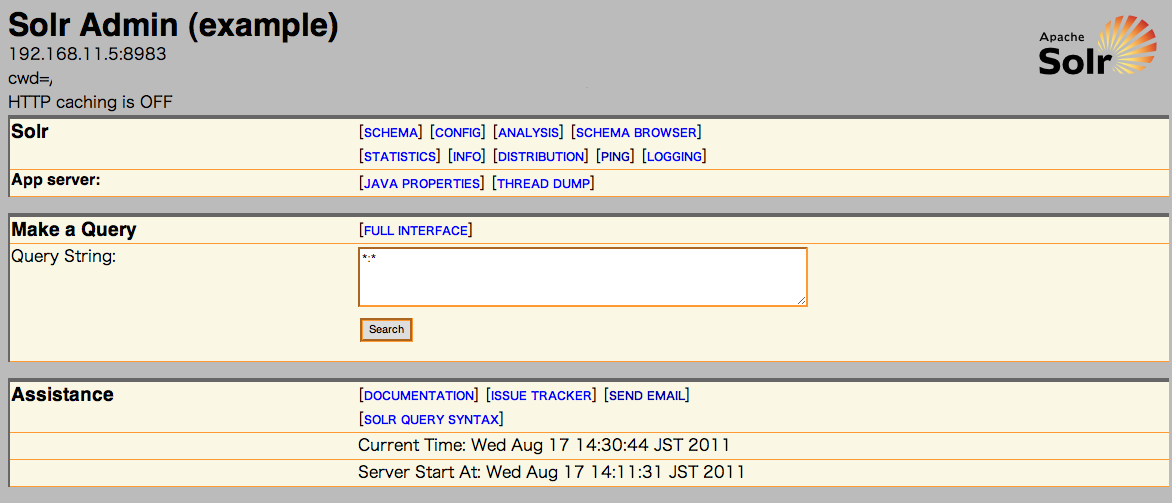
2. 画面中央のsearchボタンを押します。
検索結果が返ってきます。
(または次のように検索します。)

以上で、ManifoldCFでWebサーバのクロールを行って、Solrでの検索結果を確認しました。
ManifoldCFの管理画面から設定を行い、実際にクロールを実行して動作を確認します。
Webサーバ接続によるクロールの特長
ManifoldCFでは、一般的なWebクローラの機能を持っています。HTMLやRSSフィードからリンクを抽出して、HTMLだけでなくリンク先にあるドキュメントをクロールすることができます。そして、そのドキュメントからコンテンツを抽出して、Solrでインデクシングすることができます。企業内のWebサーバで情報共有している社内ポータルの検索や社内管理文書を検索する、といったケースにManifoldCFを使うことができます。Solrと連携してWebのドキュメントの検索を行います。
準備
- 「Apache ManifoldCF -セットアップ-」に記載されているセットアップ作業を実施します。
- クロール対象のWebサーバを用意します。今回の例では、ロンウイットのダウンロードページをクロールします。
- HTMLがあり、MS Officeファイル、PDFファイルなどがリンクされています。
ManifoldCFの管理画面
各コネクタを指定してコネクションを作成し、コネクションをひとつのジョブにまとめます。そして、ジョブで各種項目を設定し、実行することでクロールが実行されます。
今回は、各コネクタを次のように設定します。
WindowsサーバをクロールしてデータをSolrに渡すという流れです。
- アウトプット → Solr
- オーソリティ → Null
- レポジトリ → Web
1. ManifoldCFの管理画面を表示します。
http://localhost:8345/mcf-crawler-ui
2. List Output Connectionsを選択し、コネクションをAddします。
Nameに「Solr」(任意)を入力し、Typeに「Solr」を選択します。
Continueボタンを押してSolrに関する詳細設定が表示されますが
デフォルトのままで動作するので、変更しません。
最後にSaveボタンを押します。
3. List Authority Connectionsを選択し、コネクションをAddします。
Nameに「Null」(任意)を入力し、Typeに「Null」を選択します。
最後にSaveボタンを押します。
4. List Repository Connectionsを選択し、コネクションをAddします。
Nameに「Web」(任意)を入力し、
Typeに「Web」を選択し、Authorityに「Null」を選択します。
Emailタブで、メールアドレスを入力します。
最後にSaveボタンを押します。
5. List all Jobsを選択し、ジョブをAddします。
Connectionタブで、登録済みコネクションを指定します。
Outputに「Solr」、Repositoryに「Web」を選択します。
Continueボタンを押してジョブに関する詳細設定が表示されます。
Seedsタブでクロール対象の起点となるURLを入力します。
Inclusionsタブでクロール対象のURL等を入力します。
Exclusionsタブでクロール除外対象のURL等を入力します。
最後にSaveボタンを押します。
6. Status and Job Managementを選択します。
登録済みジョブのStartをクリックして、クロールを実行します。
Refreshをクリックするとでジョブの経過を確認することができます。
ステータスにDoneが表示されるとクロールのジョブが終了したことになります。
7. SimpleHistoryを選択します。
レポジトリを選択してContinueボタンを押します。
ジョブの開始終了、リンクおよびドキュメントのアクセスとSolrへの投入状況など
クロール履歴を確認することができます。
Solrの管理画面
SolrではManifoldCFから渡されてきたデータをインデクシングします。すでに前述までの過程でインデクシングが完了しています。
ここでは、検索を行って内容を確認します。
1. Solrの管理画面を表示します。
http://localhost:8983/solr/admin
2. 画面中央のsearchボタンを押します。
検索結果が返ってきます。
(または次のように検索します。)
http://localhost:8983/solr/select/?q=*:*&fl=id,text&start=0&rows=20textフィールドにHTMLやリンク先のドキュメントのコンテンツが登録されていることを確認します。
以上で、ManifoldCFでWebサーバのクロールを行って、Solrでの検索結果を確認しました。
INFORMATION
KandaSearch
KandaSearch はクラウド型企業向け検索エンジンサービスです。
オープンAPIでカスタマイズが自由にできます。
セミナー
企業が検索エンジンを選定する際のポイントから、
実際の導入デモをお客様ご自身でご体験!