INFORMATION
テクノロジ
Apache ManifoldCF -ファイルサーバのクロール-
今回はApache ManifoldCFのファイルサーバのクロールをご説明します。
今回から、ManifoldCFの管理画面から設定を行い、実際にクロールを実行して動作を確認します。
逆に言えば、準備がほとんど不要で、管理画面の設定が簡単なのですぐに利用できること、個人用デスクトップクローラ、デスクトップサーチとして利用できること、という特長があります。
そして、ジョブで各種項目を設定し、実行することでクロールが実行されます。
今回は、各コネクタを次のように設定します。
ファイルサーバをクロールしてデータをSolrに渡すという流れです。
1. ManifoldCFの管理画面を表示します。
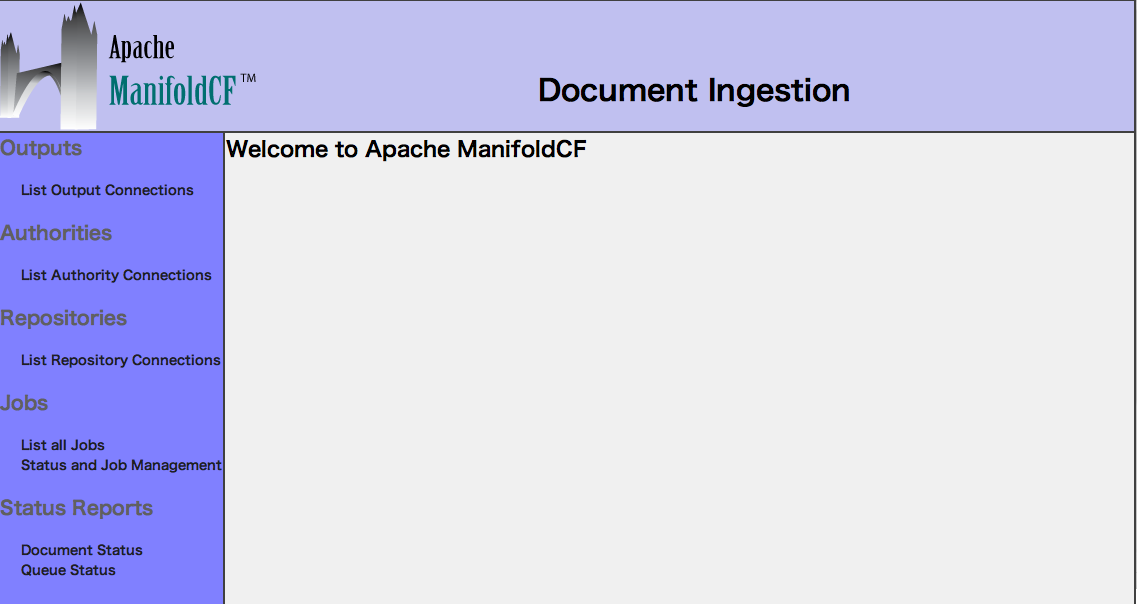
2. List Output Connectionsを選択し、コネクションをAddします。
Nameに「Solr」(任意)を入力し、Typeに「Solr」を選択します。
Continueボタンを押してSolrに関する詳細設定が表示されますが
デフォルトのままで動作するので、変更しません。
最後にSaveボタンを押します。
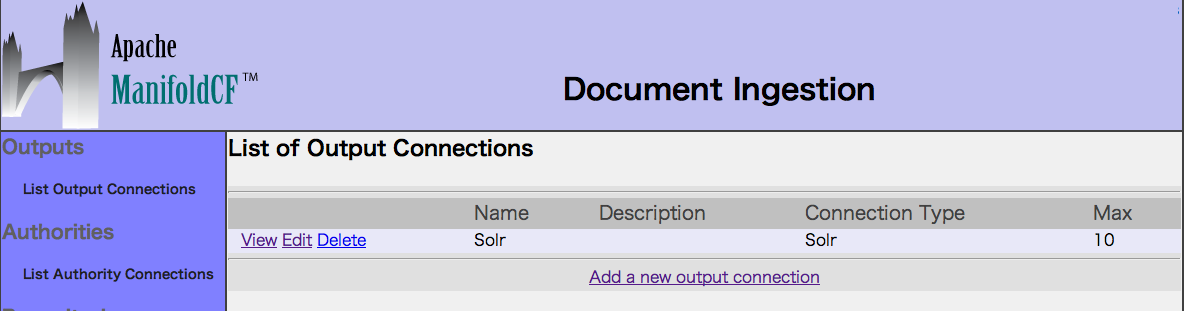
3. List Authority Connectionsを選択し、コネクションをAddします。
Nameに「Null」(任意)を入力し、Typeに「Null」を選択します。
最後にSaveボタンを押します。
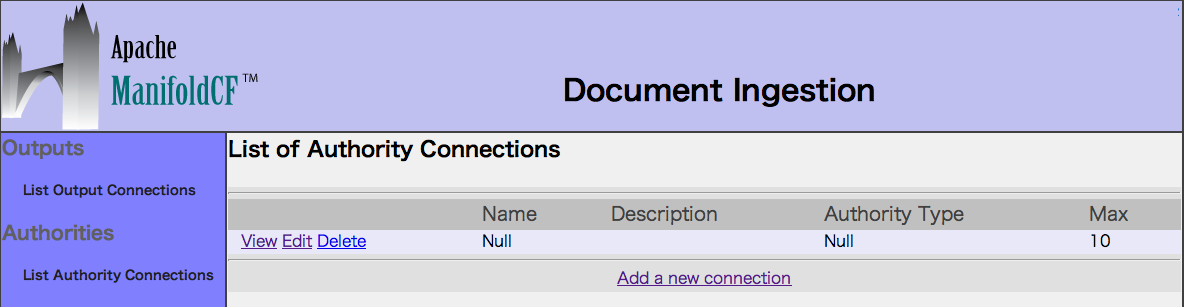
4. List Repository Connectionsを選択し、コネクションをAddします。
Nameに「File system」(任意)を入力し、
Typeに「File system」を選択し、Authorityに「Null」を選択します。
最後にSaveボタンを押します。
5. List all Jobsを選択し、ジョブをAddします。
Connectionタブで、登録済みコネクションを指定します。
Outputに「Solr」、Repositoryに「File system」を選択します。
Continueボタンを押してジョブに関する詳細設定が表示されますが
ここでは、Pathsタブでクロール対象のフォルダパスを入力しAddします。
最後にSaveボタンを押します。
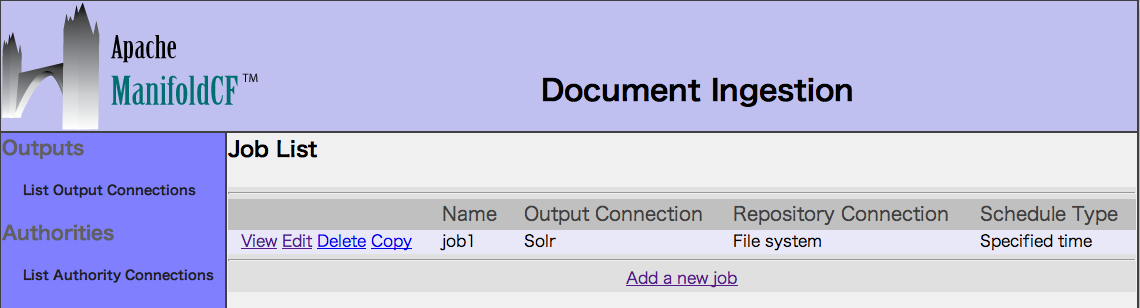
6. Status and Job Managementを選択します。
登録済みジョブのStartをクリックして、クロールを実行します。
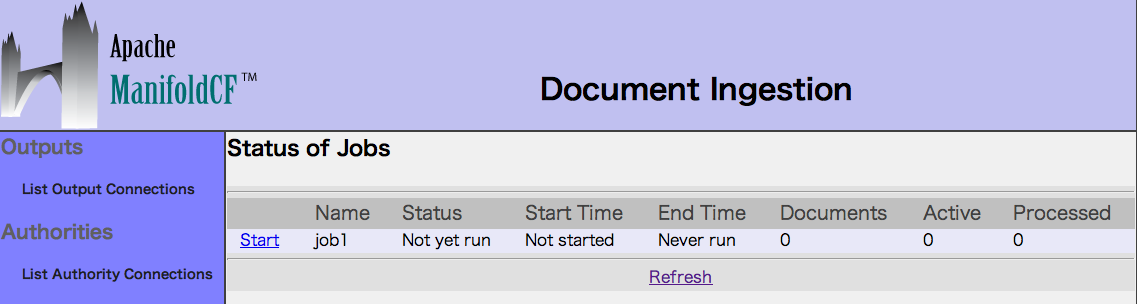
Refreshをクリックするとでジョブの経過を確認することができます。
ステータスにDoneが表示されるとクロールのジョブが終了したことになります。
7. SimpleHistoryを選択します。
レポジトリを選択してContinueボタンを押します。
ジョブの開始終了、フォルダおよびドキュメントの、アクセスとSolrへの投入状況など
クロール履歴を確認することができます。
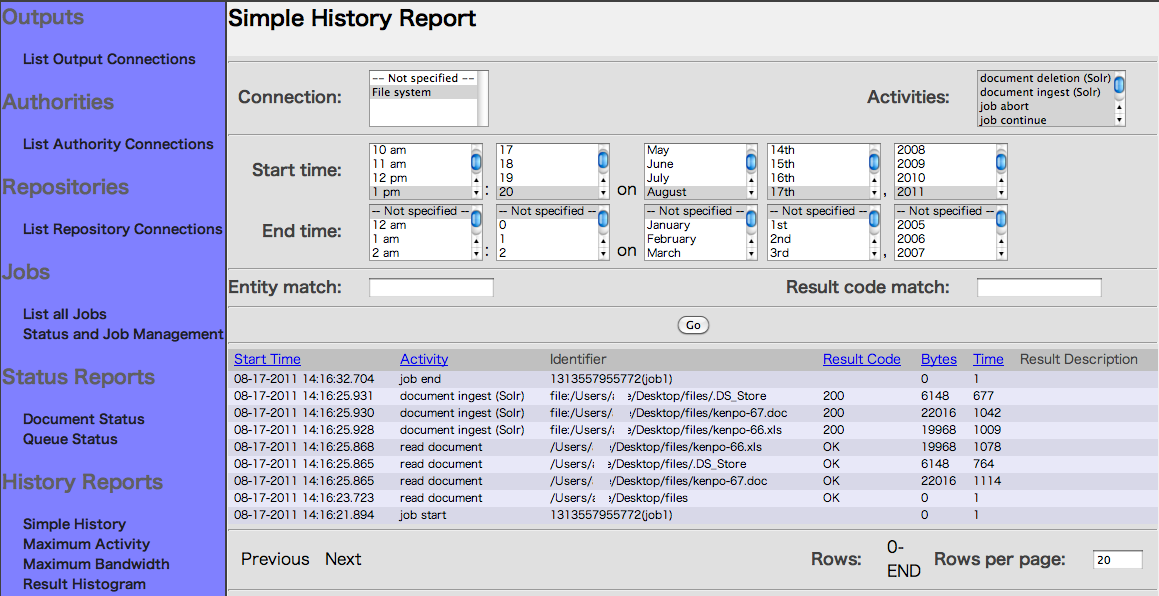
すでに前述までの過程でインデクシングが完了しています。
ここでは、検索を行って内容を確認します。
1. Solrの管理画面を表示します。
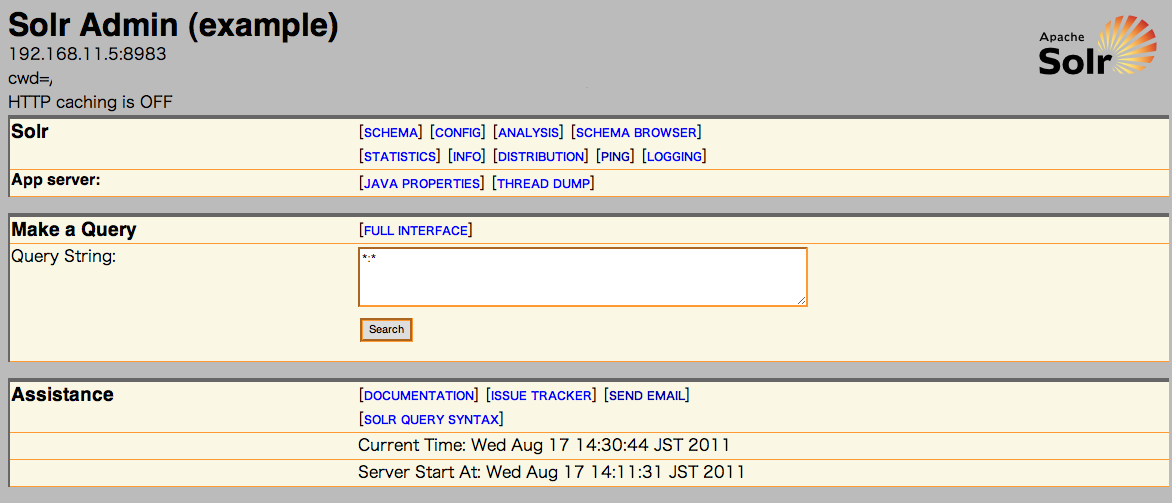
2. 画面中央のsearchボタンを押します。
検索結果が返ってきます。
textフィールドにファイルのコンテンツが登録されていることを確認します。
attr_*フィールドにファイル属性が登録されていることを確認します。

以上で、ManifoldCFでファイルサーバのクロールを行って、Solrでの検索結果を確認しました。
SolrへのドキュメントのPOSTは、一般的には加工済みXMLファイルをPOSTしたり、
HTTPリクエストに直接入力してPOSTしたり、SolrJを利用したクライアントプログラムを作成したりして、
事前にPOSTするための加工作業が必要となるケースが多いです。
しかし、ManifoldCFを利用すれば、上記のような作業をスキップすることができ、
エクセルやワードやPDFなど、実物のファイルをほぼ自動的にPOSTすることができます。
次回は、Windows共有サーバのクロールをご説明します。
今回から、ManifoldCFの管理画面から設定を行い、実際にクロールを実行して動作を確認します。
ファイルサーバ接続によるクロールの特長
もともとデモ用やテスト用に開発されたため、ローカルサーバが対象でありリモートサーバは対応できないこと、ファイルのセキュリティを考慮していないこと、設定項目が限定的であること、などの制限があります。(なお、このような制限は、次回説明するWindows共有サーバのクロールにはなく、より実践的に利用することができます。)逆に言えば、準備がほとんど不要で、管理画面の設定が簡単なのですぐに利用できること、個人用デスクトップクローラ、デスクトップサーチとして利用できること、という特長があります。
準備
- 「Apache ManifoldCF -セットアップ-」に記載されているセットアップ作業を実施します。
- ManifoldCFがセットアップされたPC、その中にクロール対象のフォルダやファイルを用意します。
- ファイルは、テキストファイル、MS Officeファイル、PDFファイルなどを用意します。
ManifoldCFの管理画面
各コネクタを指定してコネクションを作成し、コネクションをひとつのジョブにまとめます。そして、ジョブで各種項目を設定し、実行することでクロールが実行されます。
今回は、各コネクタを次のように設定します。
ファイルサーバをクロールしてデータをSolrに渡すという流れです。
- アウトプット → Solr
- オーソリティ → Null
- レポジトリ → File system
1. ManifoldCFの管理画面を表示します。
http://localhost:8345/mcf-crawler-ui
2. List Output Connectionsを選択し、コネクションをAddします。
Nameに「Solr」(任意)を入力し、Typeに「Solr」を選択します。
Continueボタンを押してSolrに関する詳細設定が表示されますが
デフォルトのままで動作するので、変更しません。
最後にSaveボタンを押します。
3. List Authority Connectionsを選択し、コネクションをAddします。
Nameに「Null」(任意)を入力し、Typeに「Null」を選択します。
最後にSaveボタンを押します。
4. List Repository Connectionsを選択し、コネクションをAddします。
Nameに「File system」(任意)を入力し、
Typeに「File system」を選択し、Authorityに「Null」を選択します。
最後にSaveボタンを押します。
5. List all Jobsを選択し、ジョブをAddします。
Connectionタブで、登録済みコネクションを指定します。
Outputに「Solr」、Repositoryに「File system」を選択します。
Continueボタンを押してジョブに関する詳細設定が表示されますが
ここでは、Pathsタブでクロール対象のフォルダパスを入力しAddします。
最後にSaveボタンを押します。
6. Status and Job Managementを選択します。
登録済みジョブのStartをクリックして、クロールを実行します。
Refreshをクリックするとでジョブの経過を確認することができます。
ステータスにDoneが表示されるとクロールのジョブが終了したことになります。
7. SimpleHistoryを選択します。
レポジトリを選択してContinueボタンを押します。
ジョブの開始終了、フォルダおよびドキュメントの、アクセスとSolrへの投入状況など
クロール履歴を確認することができます。
Solrの管理画面
SolrではManifoldCFから渡されてきたデータをインデクシングします。すでに前述までの過程でインデクシングが完了しています。
ここでは、検索を行って内容を確認します。
1. Solrの管理画面を表示します。
http://localhost:8983/solr/admin
2. 画面中央のsearchボタンを押します。
検索結果が返ってきます。
textフィールドにファイルのコンテンツが登録されていることを確認します。
attr_*フィールドにファイル属性が登録されていることを確認します。
以上で、ManifoldCFでファイルサーバのクロールを行って、Solrでの検索結果を確認しました。
SolrへのドキュメントのPOSTは、一般的には加工済みXMLファイルをPOSTしたり、
HTTPリクエストに直接入力してPOSTしたり、SolrJを利用したクライアントプログラムを作成したりして、
事前にPOSTするための加工作業が必要となるケースが多いです。
しかし、ManifoldCFを利用すれば、上記のような作業をスキップすることができ、
エクセルやワードやPDFなど、実物のファイルをほぼ自動的にPOSTすることができます。
次回は、Windows共有サーバのクロールをご説明します。
INFORMATION
KandaSearch
KandaSearch はクラウド型企業向け検索エンジンサービスです。
オープンAPIでカスタマイズが自由にできます。
セミナー
企業が検索エンジンを選定する際のポイントから、
実際の導入デモをお客様ご自身でご体験!