INFORMATION
ニュース
Scale By the Bay 2017に参加してきました。(二日目&三日目)
溝口 泰史 著
前回に引き続き、Scale By the Bayの二日目、三日目のセッションのレポートです。
二日目
Composable Parallel Processing in Apache Spark and Weld
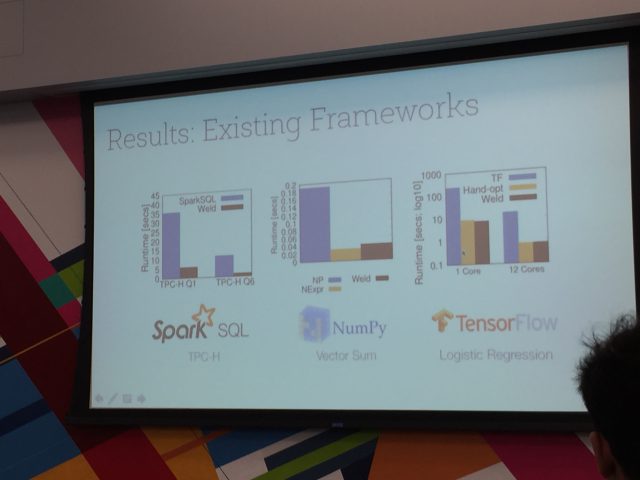
二日目の基調講演で、Apache Sparkの創始者の一人、Matei Zahariaさんが登壇しました。
内容はSparkとHadoopとの比較(開発のモチベーション)、Data structured API、データの持ち方の変更(RDD -> DataFrame)による性能向上について簡単に説明したのちに、Mateiさんが開発に携わっているWeldをSparkの処理に適用した際の性能向上について説明すると言うものでした。
Sparkはご存知の通り、大規模なデータの分散処理を効率化するものとして様々なところで採用されていますが、Weldはその処理で利用される個々の命令を中間表現(IR:intermediate representation)に変換し、それらを最適化することで処理速度の大幅な向上を目指すというものでした。論文に載っている結果比較のグラフを見る限りでは、その効果は人手でコードを最適化した場合と遜色のないもののように思えます。
また、WeldはSparkだけではなくTensor Flowなど他のフレームワークでも利用できるものがあるとのことで、今後の発展が期待できます。
Apache SystemML: State of the Project and Future Plans
IBMが主導して進めている、Apache SystemMLプロジェクトについての発表でした。
SystemMLは先日IncubatorからTop Level Projectに昇格したプロジェクトで、特にSparkの処理における線形代数計算の効率化を目指しているプロジェクトです。(ちなみに私はこのセッションで初めて存在を知りました。)
機械学習の処理において線形代数計算は多用されています。ただし、機械学習で利用されるような非常に大きなデータでは扱う行列やベクトルの次元も大きくなりがちで、フレームワーク側には巨大な行列やベクトルを限られたメモリ空間の中で処理することが求められます。
SystemMLではそれらに対して数学とコンピュータ双方のアプローチで改善を行なっているとのことで、それらの紹介が主なところでした。それらの改善のうち、私個人として最も印象的だったのがDBの圧縮技術を利用してデータを圧縮し、それをそのまま演算することでメモリ使用量の低減と処理速度の向上を図ったと言うものでした。
上記2つ以外のセッションでも見受けられましたが、今回大規模データを扱う性能向上をしたと言う内容のセッションでは、概して他の分野で実績のある手法を用いてSparkやTensor Flowの処理速度の向上を図ったと言う内容のものが多かったように思えます。Weldは論文内でLLVM(Low Level Virtual Machine、コンパイル時に内部で中間命令を生成と改善を繰り返して高速なコードを生成するコンパイラ)をコンパイラのバックエンドで利用していると書いてありますし、SystemMLのアプローチは上述の通りDBで実績のある手法です。
このことから、SparkやTensor Flowなどハードウェアの進歩によって実現した新しいソフトウェアアーキテクチャに対しても既存の高速化の手法を用いると言うのは十分に有効で、今後もしばらくはそのような手法を用いて処理速度を向上させられるのだろうと感じました。
Scala 2.13 & Beyond

読んで字のごとく、Scala 2.13とその先のリリースについてのセッションでした。
冒頭で参加者が利用しているScalaのバージョンを尋ねていたのですが、ほとんど全員が未だに2.11(Scala 2.11がSparkでサポートされている最新のScalaのため)を使っているとのことで、ダウンロード数を見ても2.12への移行はあまり進んでいなさそうでした。
Scalaの(マイナーアップデートの)リリースサイクルは日々早まってきており、Scala 2.13は2018年の1月にリリース予定で、大きな変更点としては公式ページのロードマップにある通り以下の三つのようです。(ヘッドラインにはSmaller core libとありましたが、説明はこれら3つに比べて少なかったので、割愛しました。)
Collection APIが既存の書き方との互換性に注意を払いつつ、よりシンプルで直感的な操作が可能になる
scala-coreのコンパイル速度が25%改善された
ドキュメントの充実とツールを充実させた(REPL周りの項目が多かった気がします。)
Building a high-performance Future
タイトルが面白かったのと、前日のTwitterの方のセッションが面白かったので参加しました。なお、FutureとはScalaのFutureのことです。
Futureは主に非同期のIOを扱う場合の処理結果を収めるために利用されます。この仕組みはプログラムを作るときには助かるのですが、内部の処理は複雑なものになっていてということでFutureの新たな実装を作ったとのことです。詳しい説明はtrane.ioのページに載っているので割愛しますが、以下に挙げるツールを使って性能を改善(最大18%のメモリアロケーションの削減と最大50%のスループットの向上)したとのことで、そのチューニングの話が聞けたのがよかったです。
三日目
Apache Flink and the Next Wave of Stream Processing Applications

三日目の基調講演です。Apache FlinkのPMCメンバーであるStephan Ewenさんが登壇していました。
基本的にはFlinkの説明が主でしたが、序盤でデータとビジネスロジック(クエリ)のどちらが変化しやすいかという観点で採用するべき処理(リアルタイムorバッチ)を以下のように分けていたのが面白かったです。
Flinkは上記の分類ではデータの変化が早い場合に利用されるストリーミングデータ処理の基盤です。最近では継続的に発生するデータストリームをリアルタイムに処理するということが求められてきており、Alibaba、Netflix、Uber、INGなどが利用していると紹介がありました。また、Powered by Flinkのページを見る限りでは、日本ではLINE社が利用しているようです。
今後多くの機器、センサーから得られる情報をリアルタイムに処理する必要が高まるにつれ、Flinkの重要性は高まるように思えます。 また、セッションの最後で話していた、最近データの解析処理とビジネスロジックの境界が曖昧になってきているという話は、三日目の他のセッションでも聞かれ、今後はその問題にどのように取り組んでいくのかが大規模データ処理において大きな課題となりそうだと感じました。
Stream All The Things!

タイトルに惹かれてセッションを聴きに行きました。リアルタイム処理についてデータの性質、量、そして処理結果の算出までの遅延時間ごとにどのようなアプリケーションを利用するべきかについて整理されたとても良いセッションでした。 全体的に駆け足でメモもあまり取れなかったのですが、発表に使われた(と思われる)PDFがありましたので、これから大規模データ処理基盤を構築しようとしている方は、ぜひ一度内容を確認するべきだと思います。
Scale By the Bayは、その名前の通り全体を通じて大規模なデータ解析の事例や新しいアプローチの発表が多く、大変刺激になりました。また、Scalaについてもトップクラスの開発者の知見を知ることができる、大変良い機会でした。
惜しむべくは、日本企業からの発表者が(少なくともプログラムを見る限りでは)いなかったことです。弊社では代表の関口が2015年に発表しており、次回は私もなんらかの成果を発表する立場で参加したいと思いました。
INFORMATION
KandaSearch
KandaSearch はクラウド型企業向け検索エンジンサービスです。
オープンAPIでカスタマイズが自由にできます。
セミナー
企業が検索エンジンを選定する際のポイントから、
実際の導入デモをお客様ご自身でご体験!